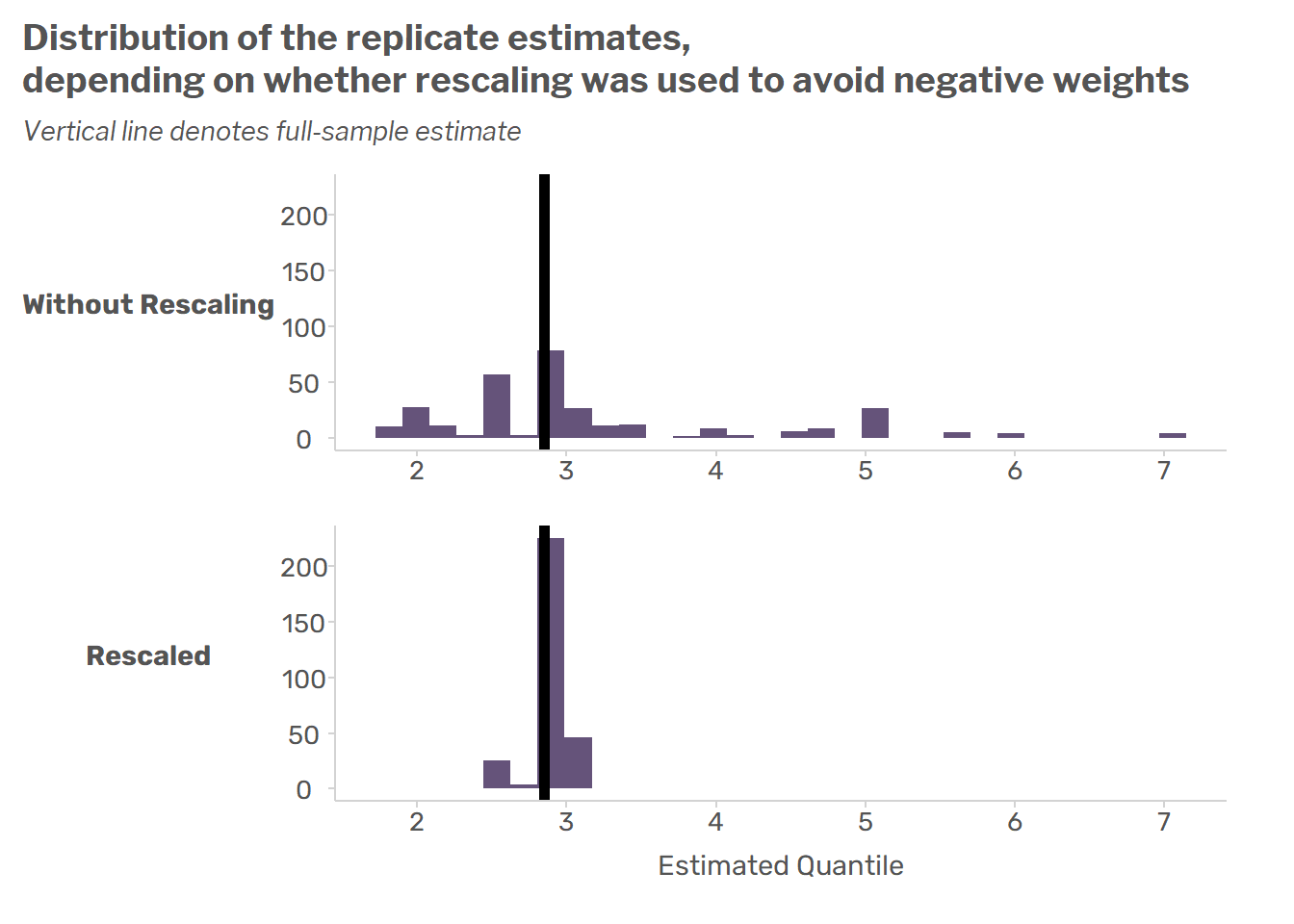
Avoiding Negative Weights in the Generalized Bootstrap
The generalized bootstrap is a promising tool for survey data, but one of the key challenges with it in practice is that it can generate negative replicate weights. This post describes the challenges posed by negative weights and demonstrates an overlooked problem with the main solutions proposed to deal with it.
An Optimization-based Bootstrap
Creating bootstrap weights for survey data can be viewed as a constrained optimization problem: obtain low-error variance estimates with as few replicates as possible using nonnegative weights. The standard solution to this problem is to use an effective but inefficent random resampling method. But what if we tried using an optimization algorithm?
More on Speeding up the Survey Package: Adding the New C++ Functions to the Package
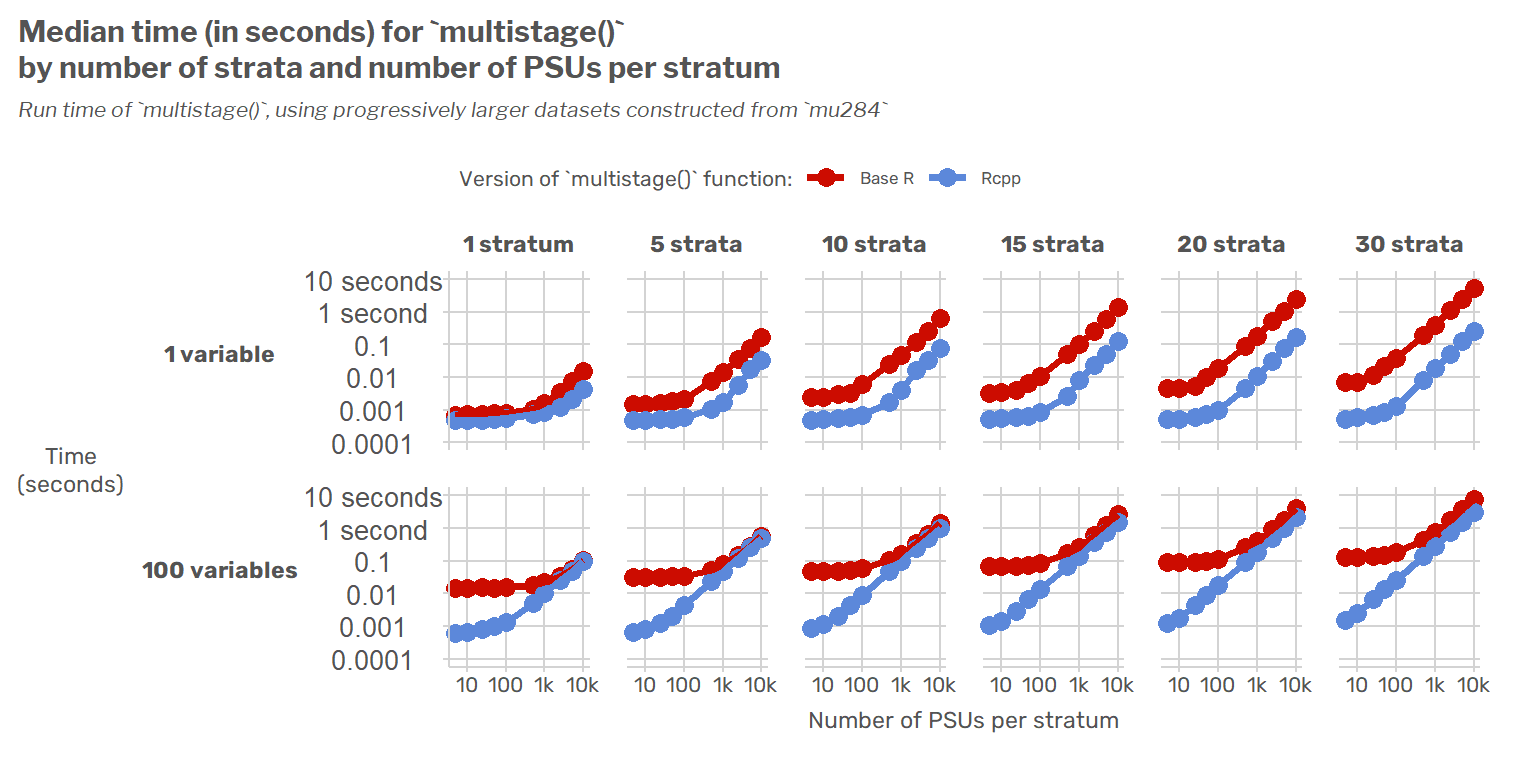
Following up on an earlier post about speeding up the {survey} package using {Rcpp} and {RcppArmadillo}, I show how the new, faster functions can be incorporated into the package along with accompanying unit tests. I also show how the speed of the original base R functions and the {Rcpp} versions scale as survey designs increase in size.
How are R and Stata (mis)handling singleton strata?
Analysts attempting to estimate variance contributions from “singleton strata” often use the “adjust”/“recentering” options implemented in R and Stata, whose meaning is unclear due to ambiguous documentation. In this post, I try to clarify what these options are actually doing in theory, and I show that in practice their software implementations have surprising bugs.

Making the {survey} package hundreds of times faster using {Rcpp}
A common objection to using the {survey} package instead of SAS or Stata is the computational time it requires. In this post, I show that we can easily obtain hundred-fold speed improvements in its core functions by using the {Rcpp} and {RcppArmadillo} packages. To illustrate, I show how we can make svytotal() run over 500 times faster. Finally, I offer thoughts about how to incorporate these {Rcpp}-based functions in either the {survey} package or a potential add-on R package.
Understanding the code used to implement the {survey} package’s recursive variance estimation for multistage samples
Unlike SAS and SPSS, the {survey} package in R can properly estimate variances for designs with multistage sampling and significant sampling fractions. The estimation is implemented using a recursive algorithm, whose basic idea is well-documented but whose R code is a bit intimidating to understand. This post walks through the R code used to implement this algorithm.
What’s the margin of error for the employee engagement index?
The key performance metric of many employee engagement surveys, the Engagement Index, is a statistic whose margin of error is deceptively difficult to estimate. As a result, many organizations fail to present a margin of error at all. I discuss why this estimation problem is difficult using the standard tools of engagement researchers, and I suggest two solutions based on tools from survey sampling theory. I provide example R code and discuss how to estimate the margin of error in general-purpose, non-statistical software.
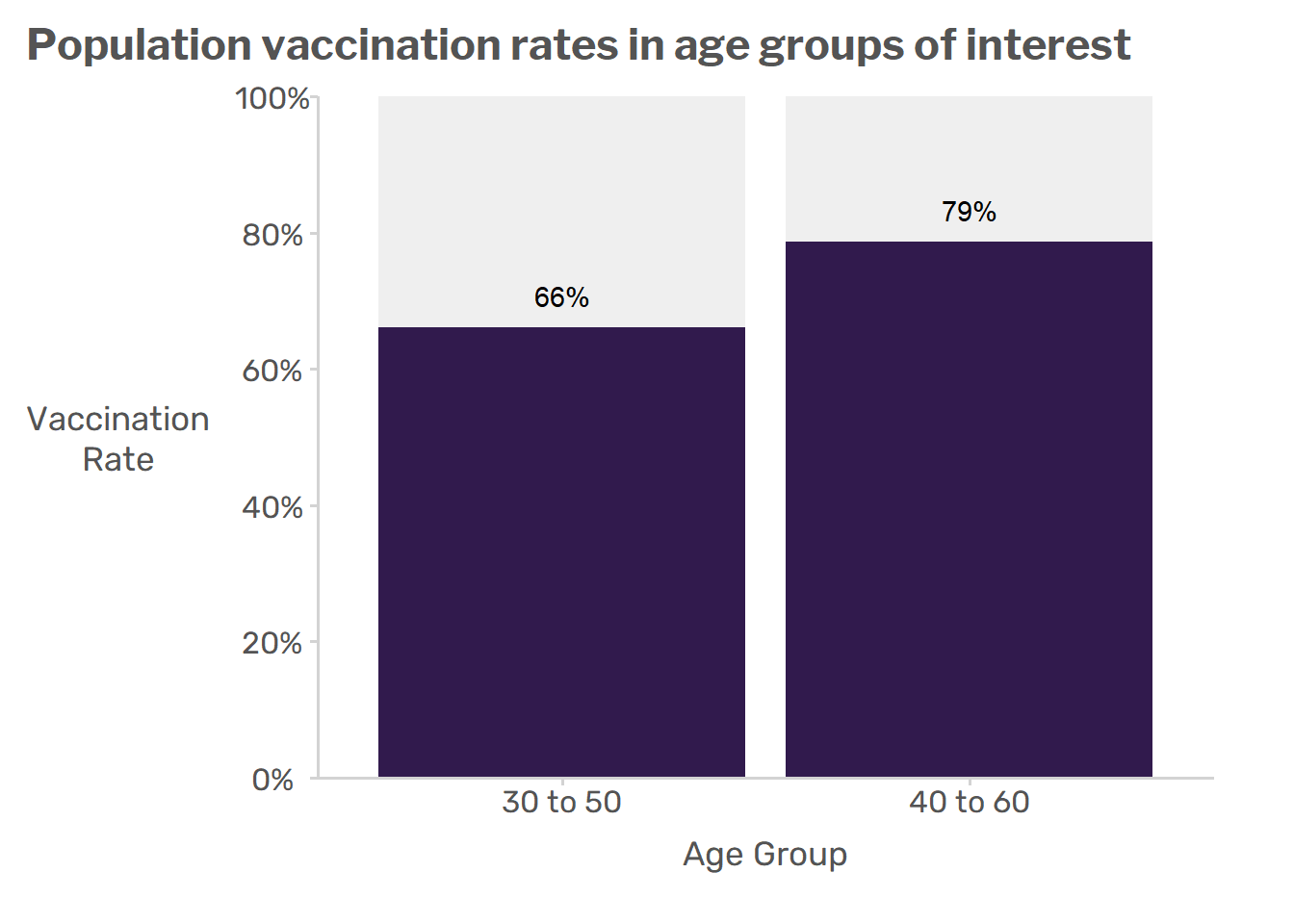
How correlated are survey estimates from overlapping groups?
We examine one approach for estimating the correlation of survey estimates from overlapping groups, such as 30-50 year olds and 40-60 year olds, using the method of linearization by influence functions. I provide a walk-through in R and use simulations to evaluate the method’s performance.

Good enough: avoiding the file drawer problem
Why I started this blog