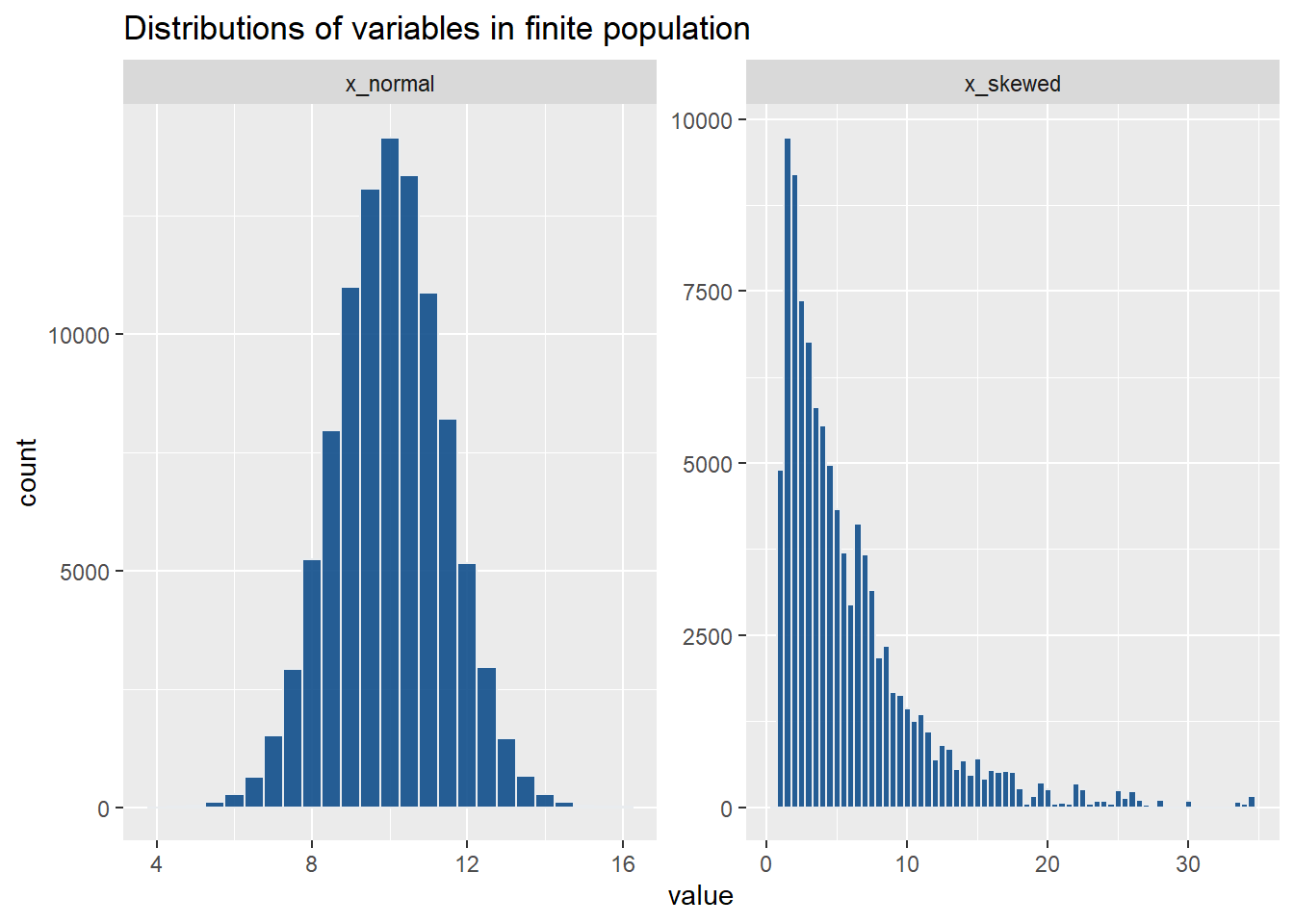
Raking A Survey to Another Survey
sampling
statistics
surveys
R
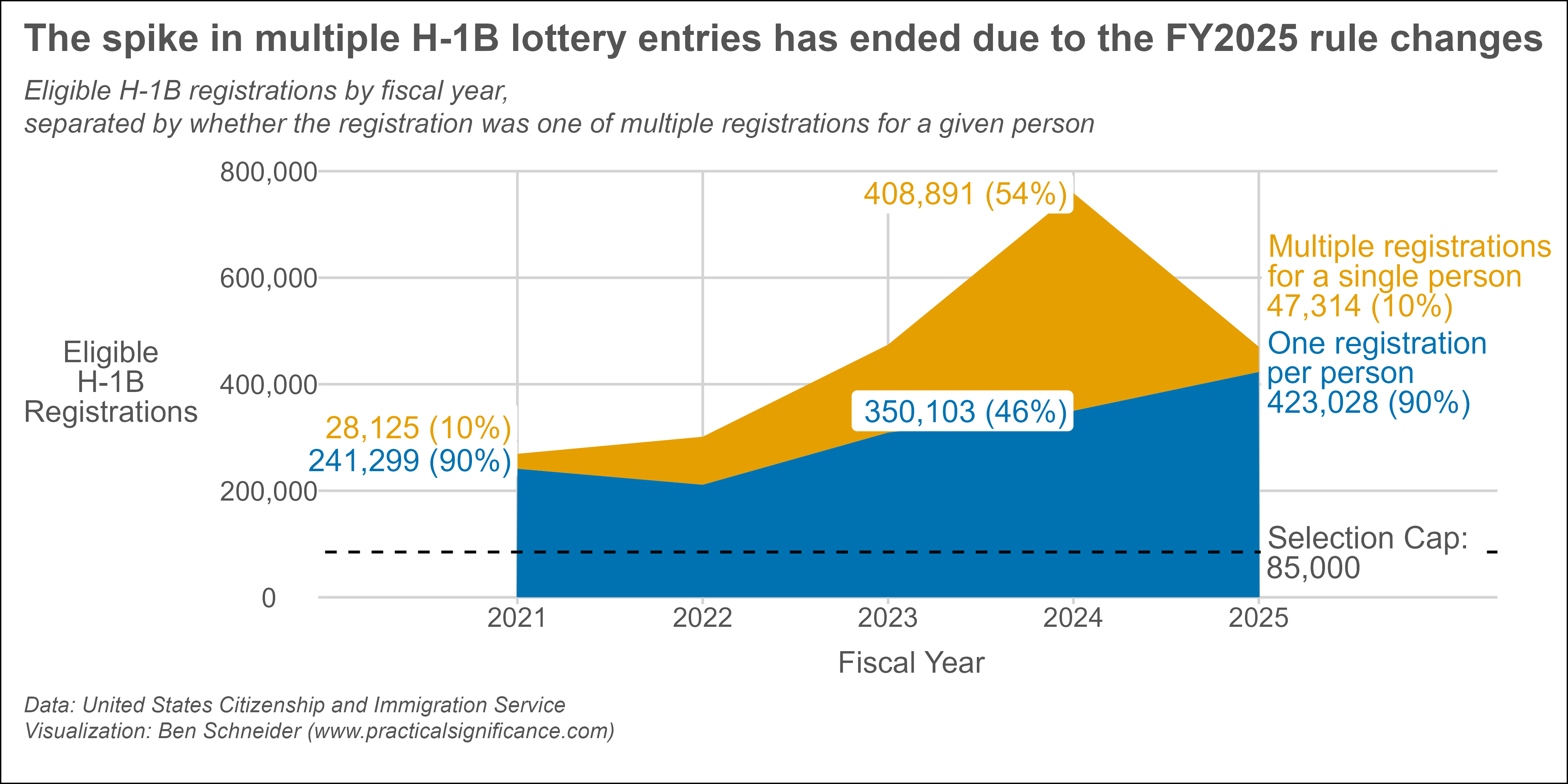
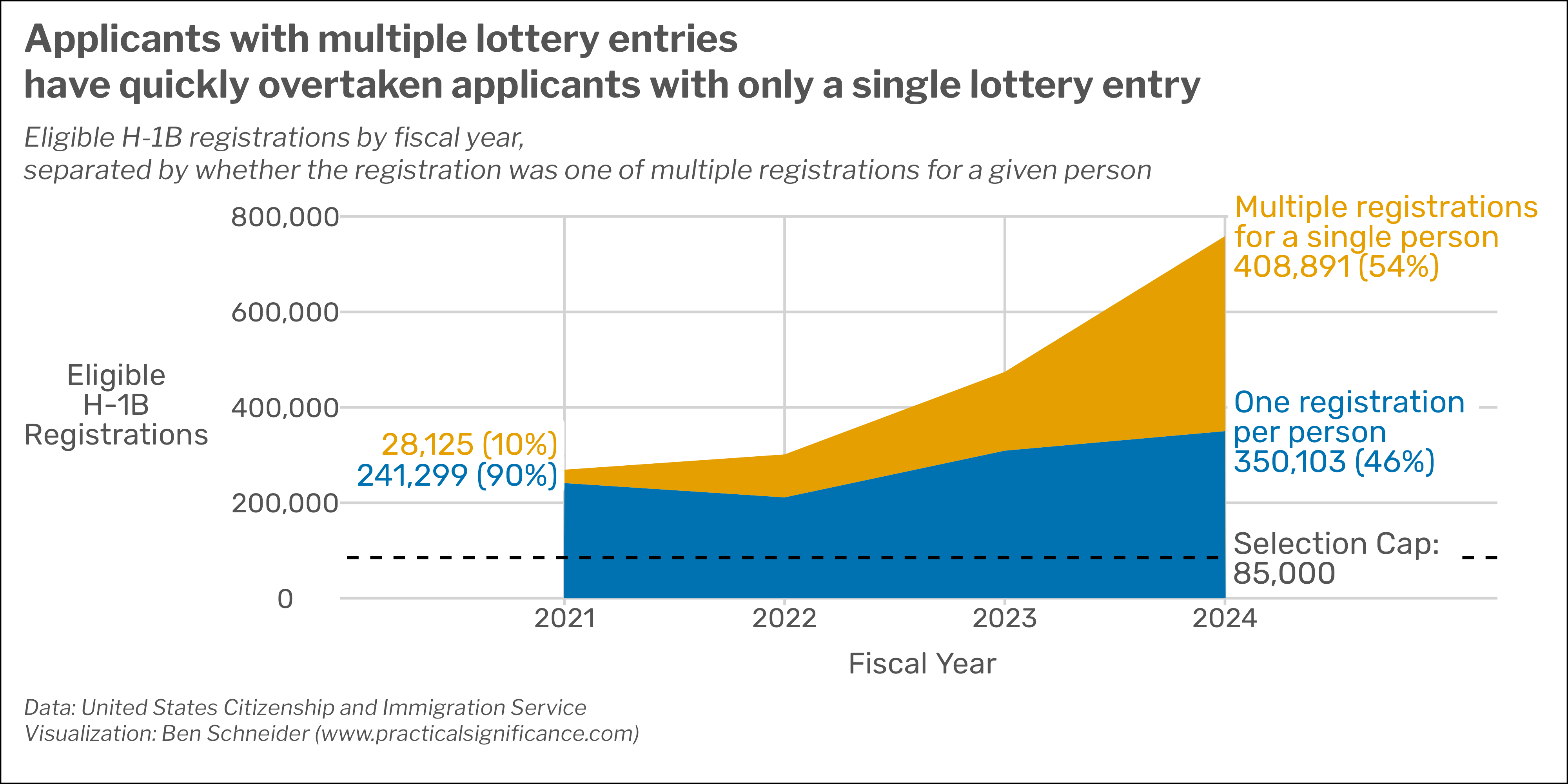
Visualizing the H-1B Fraud Spike and the Impact of Lottery Rule Changes
miscellaneous
visualization
Simulation-based Variance Estimation for the Cube Method
sampling
surveys
R
Julia
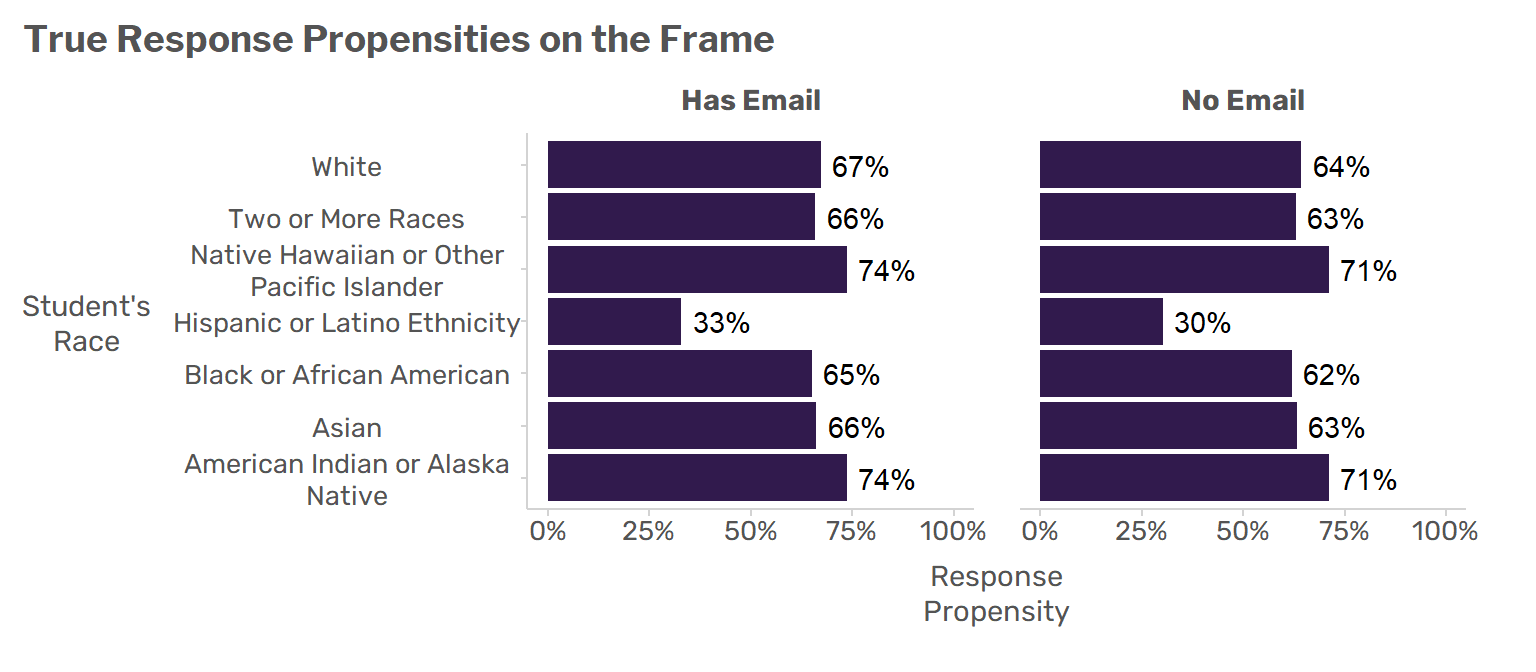
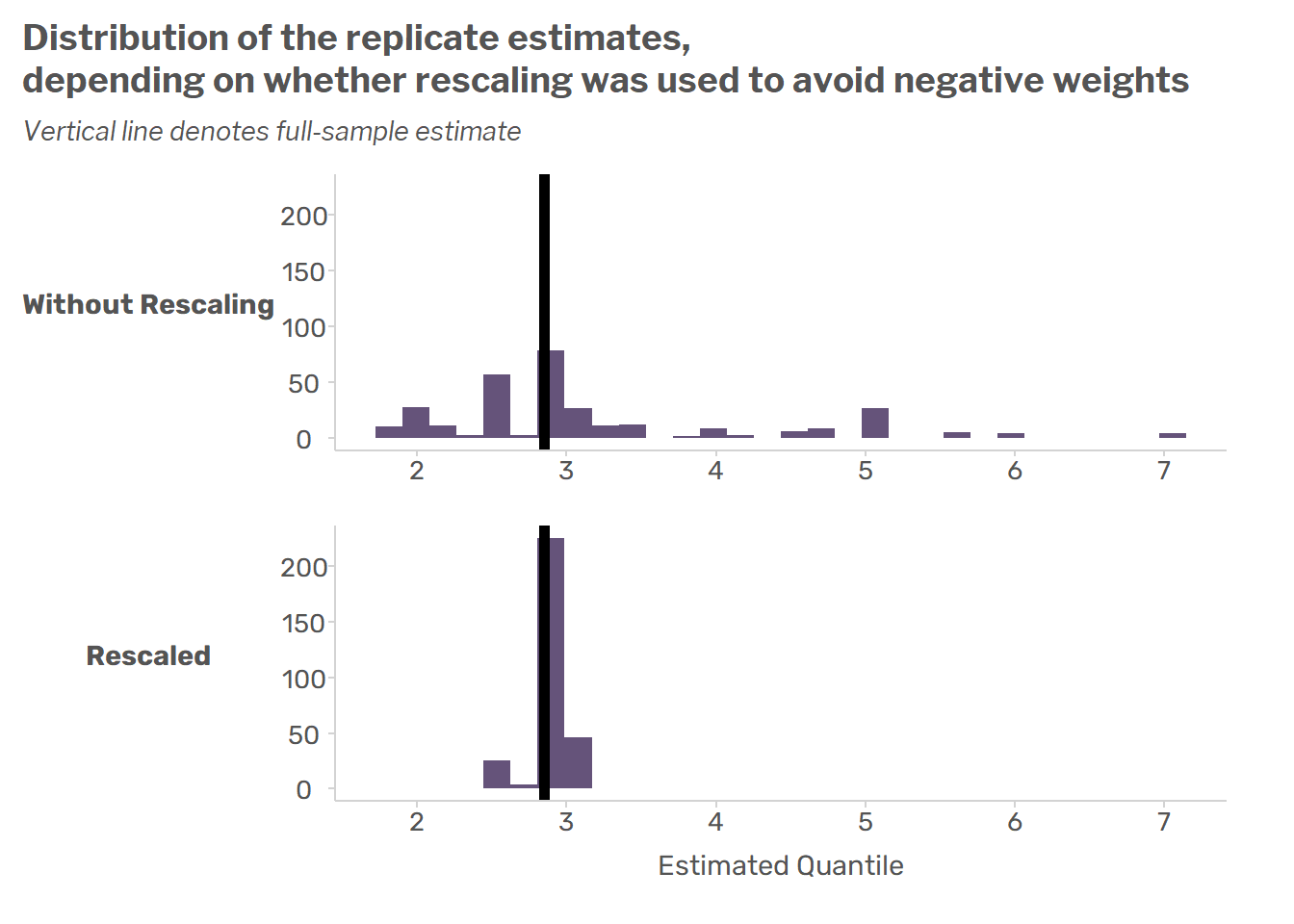
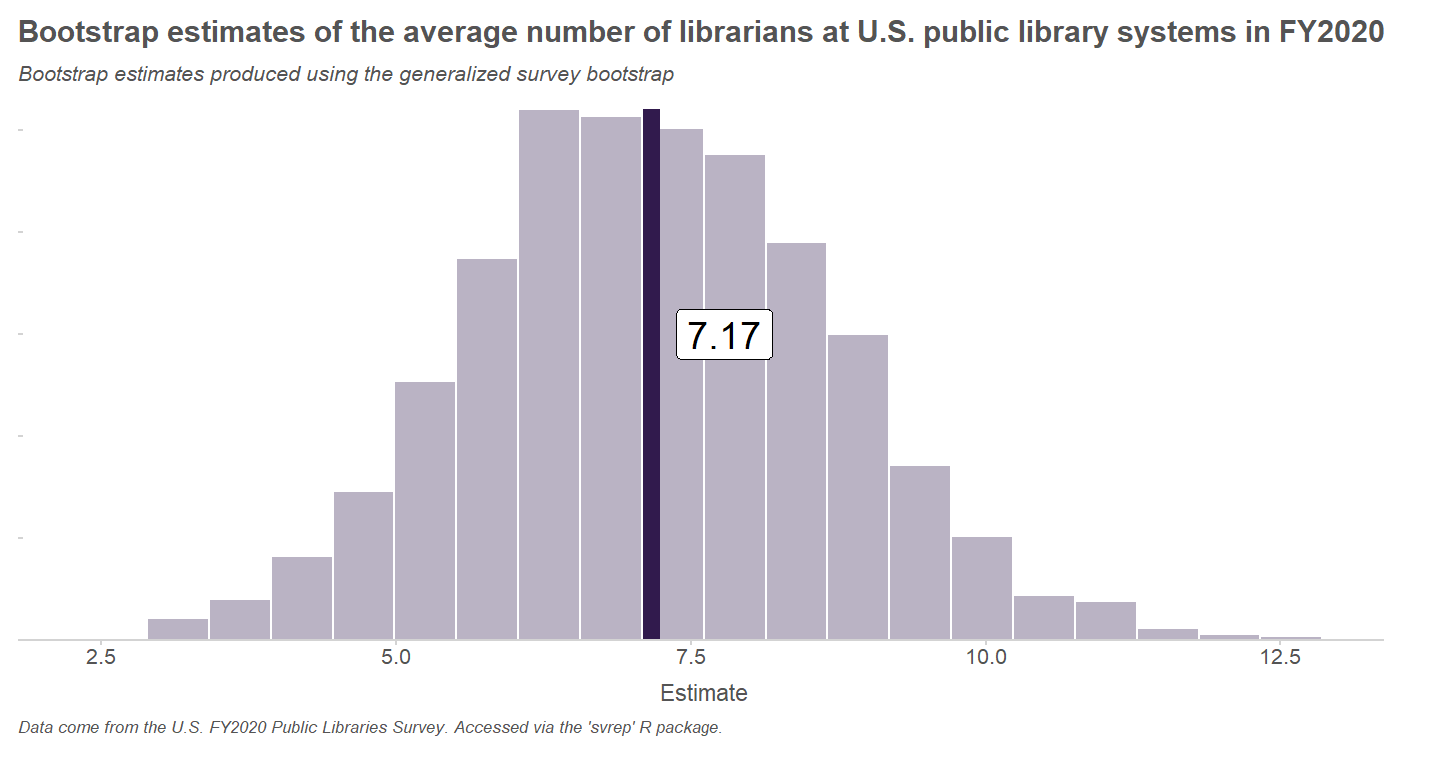
Avoiding Negative Weights in the Generalized Bootstrap
sampling
statistics
R
An Optimization-based Bootstrap
sampling
statistics
R
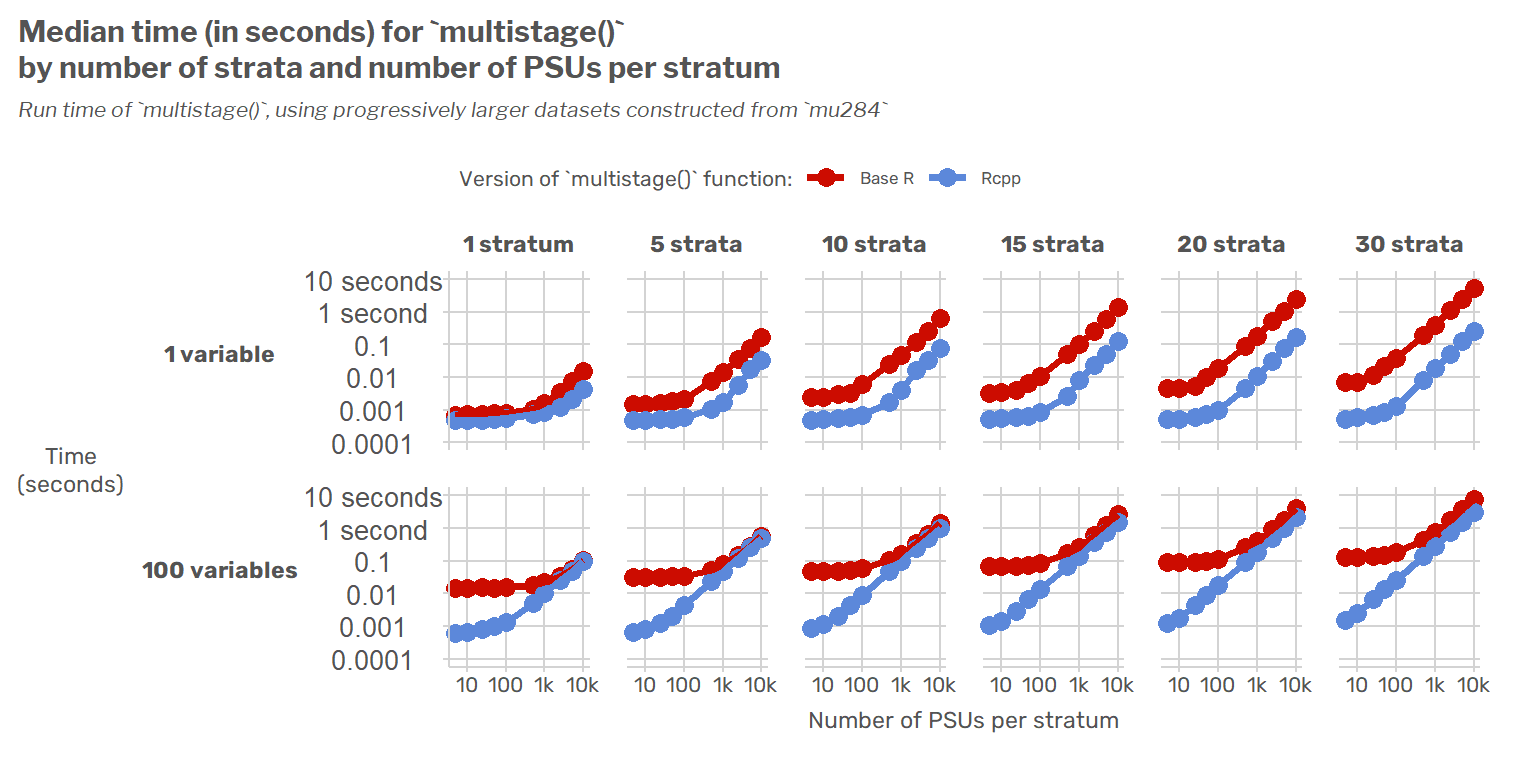
More on Speeding up the Survey Package: Adding the New C++ Functions to the Package
statistics
surveys
R
survey package
How are R and Stata (mis)handling singleton strata?
statistics
surveys
R
Stata
software

Making the {survey} package hundreds of times faster using {Rcpp}
statistics
surveys
R
survey package
Understanding the code used to implement the {survey} package’s recursive variance estimation for multistage samples
statistics
surveys
R
survey package
What’s the margin of error for the employee engagement index?
employee engagement
statistics
surveys
sampling
R
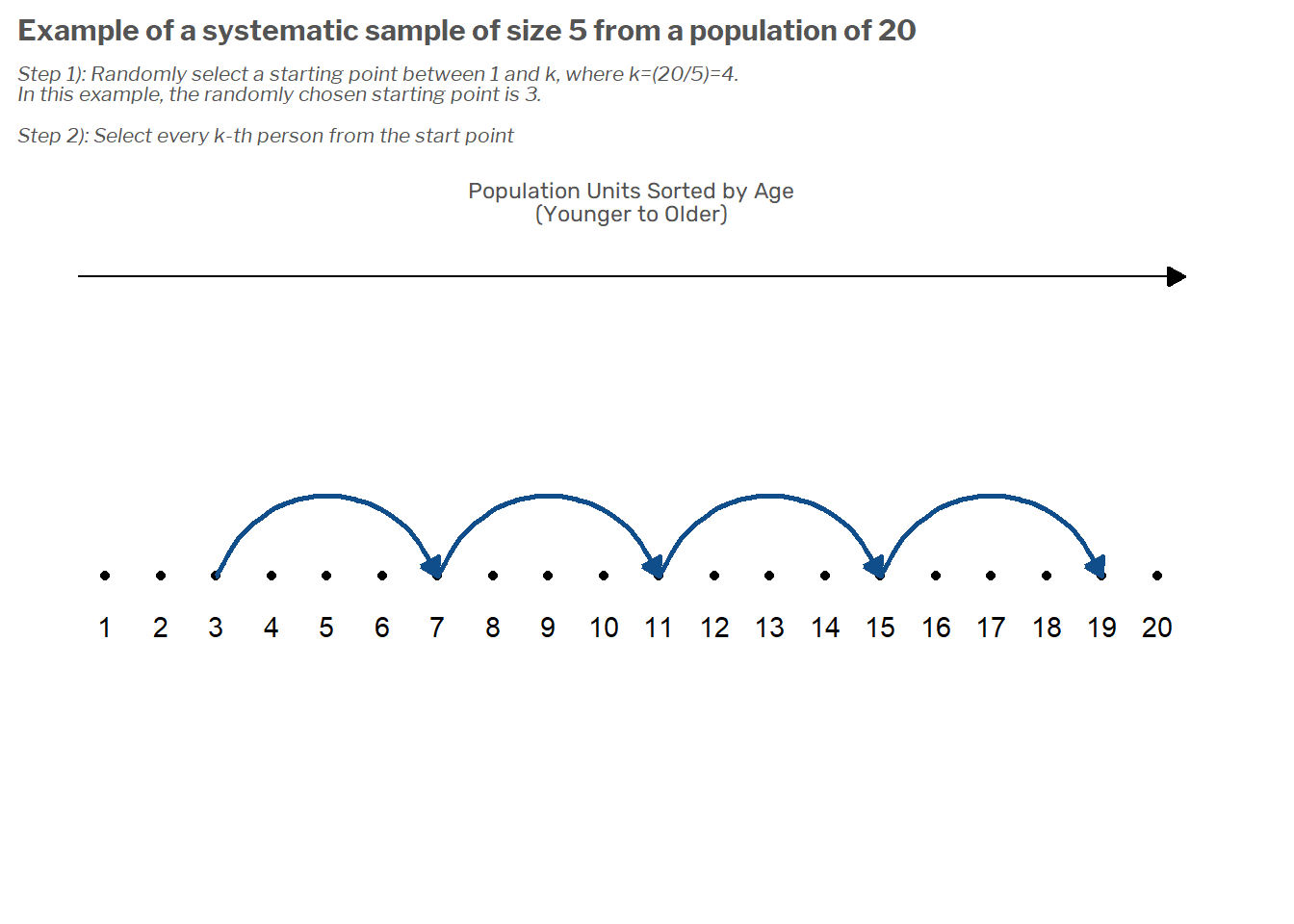
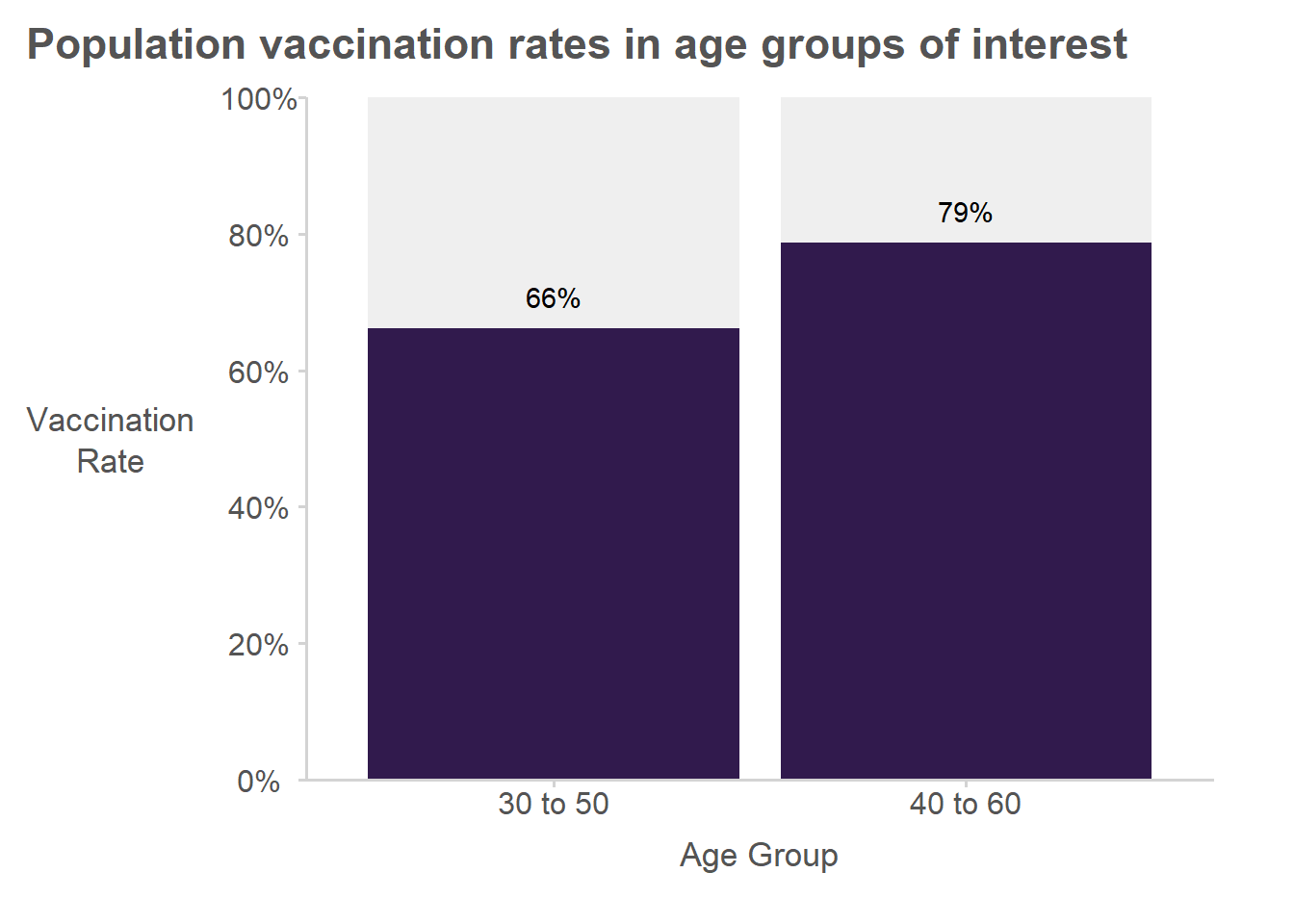
How correlated are survey estimates from overlapping groups?
statistics
surveys
sampling
simulation
R

Good enough: avoiding the file drawer problem
productivity
workflow
mentoring
No matching items